
In today’s digital age, the intersection of artificial intelligence (AI) and privacy is a critical concern. As AI-powered applications, chatbots, and large language models (LLMs) transform our interactions with technology, the need for strong privacy safeguards is more important than ever. Innovative approaches are emerging to address this challenge, offering robust anonymization and redaction capabilities to protect sensitive information, especially when interacting with AI-powered systems. By integrating advanced AI technology with effective privacy measures, these solutions create a secure platform for communication, enabling users to interact with confidence, knowing their personally identifiable information (PII) is protected. This blog post explores two privacy-preserving AI conversation methods: one using Microsoft Presidio and another leveraging a Small Language Model (SLM) combined with prompt engineering techniques.
The Privacy Challenge in AI-Driven Systems
The rapid advancement of AI and large language models has created significant opportunities for automated assistance, content generation, and information processing. However, this progress has also raised valid concerns about how sensitive information is handled in AI-driven Applications. Many users are hesitate to fully engage with AI systems due to fears of exposing personal data or confidential information to AI-Driven Systems.
Two Approaches to Privacy-Preserving AI Conversations
To address these concerns, we’ve developed an application that implements two distinct methods for ensuring privacy in AI conversations:
- Presidio-based Approach
- Small Language Model (SLM) & Prompt Engineering based Approach
Let’s explore each of these methods in detail.
Approach 1: Presidio-based Privacy Protection
What is Microsoft Presedio ?
Presidio, an open-source data protection and anonymization tool developed by Microsoft, enhances privacy and security with several notable features. It offers real-time detection of Personally Identifiable Information (PII), enabling automatic identification of sensitive data in user input. The system supports customizable anonymization, allowing users to define specific entities and rules for how data should be anonymized. Additionally, Presidio ensures transparent processing by providing clear insights into what information has been protected and the methods used.
How Microsoft Presedio works?
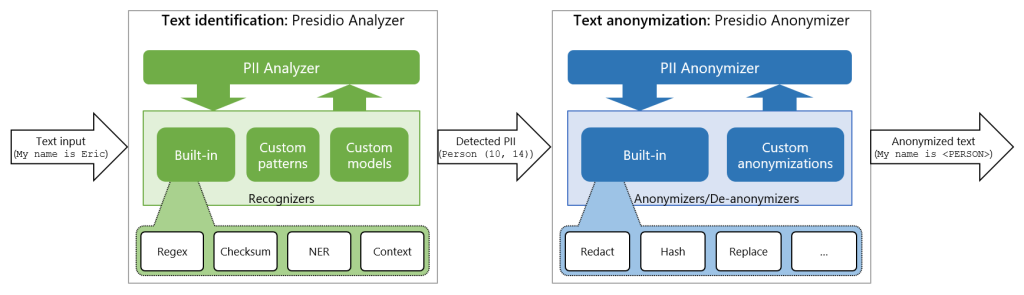
Presidio is a privacy-preserving system that operates in two main stages: identification and anonymization of Personally Identifiable Information (PII). The Presidio Analyzer first scans text inputs to detect PII using a combination of built-in recognizers, custom patterns, and models, leveraging techniques like regular expressions, Named Entity Recognition (NER), and contextual analysis. Once identified, the Presidio Anonymizer anonymizes the PII through methods such as redaction, replacement, hashing, or encryption. This process ensures that sensitive information is securely handled and protected throughout AI-driven interactions, maintaining user privacy by preventing exposure of original data to AI models.
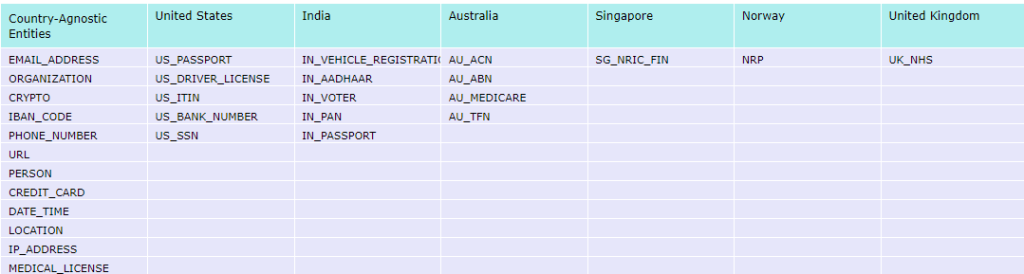
Supported Entities by Microsoft Presedio
Presidio supports a wide range of country-agnostic entities, as well as specific entities across various countries enabling robust PII detection and anonymization tailored to regional requirements.
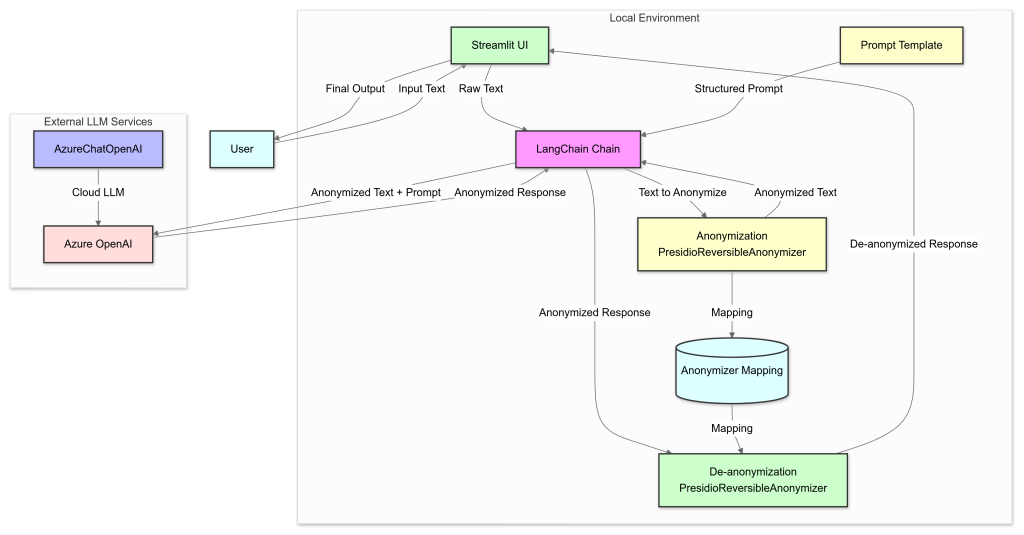
LangChain’s Presidio Wrapper Simplifies Data Anonymization
LangChain’s integration with Microsoft Presidio enhances data anonymization by seamlessly combining Presidio’s advanced features with LangChain’s framework. This integration allows developers to efficiently protect sensitive information like Personally Identifiable Information (PII) while maintaining data utility. By using Faker to replace PII with realistic dummy data, this approach makes anonymized text more natural and usable, especially in LLM-based applications. This ensures robust data protection and compliance with privacy regulations.
Advantages of the Presidio Approach
- Performance: Rapid processing.
- Resource Efficiency: Low computational requirements, ideal for edge devices or constrained environments.
- Flexibility: Customizable entity definitions and anonymization rules.
- Compliance: Aids in meeting various data protection regulations (GDPR, CCPA, etc.).
Technical Challenges
- Limited Entity Set: May require extension for highly specialized use cases.
- Rule-Based Limitations: Can struggle with novel or complex PII formats.
- Context Sensitivity: May produce false positives/negatives in ambiguous scenarios.
Enhancing Presidio’s Accuracy
To mitigate limitations and improve performance:
- Custom Entity Addition: Create specific, regex, and rule-based recognizers.
- NLP Model Integration: Incorporate suitable domain-adapted models and explore transformer-based approaches.
Approach 2: SLM & Prompt Engineering based Approach
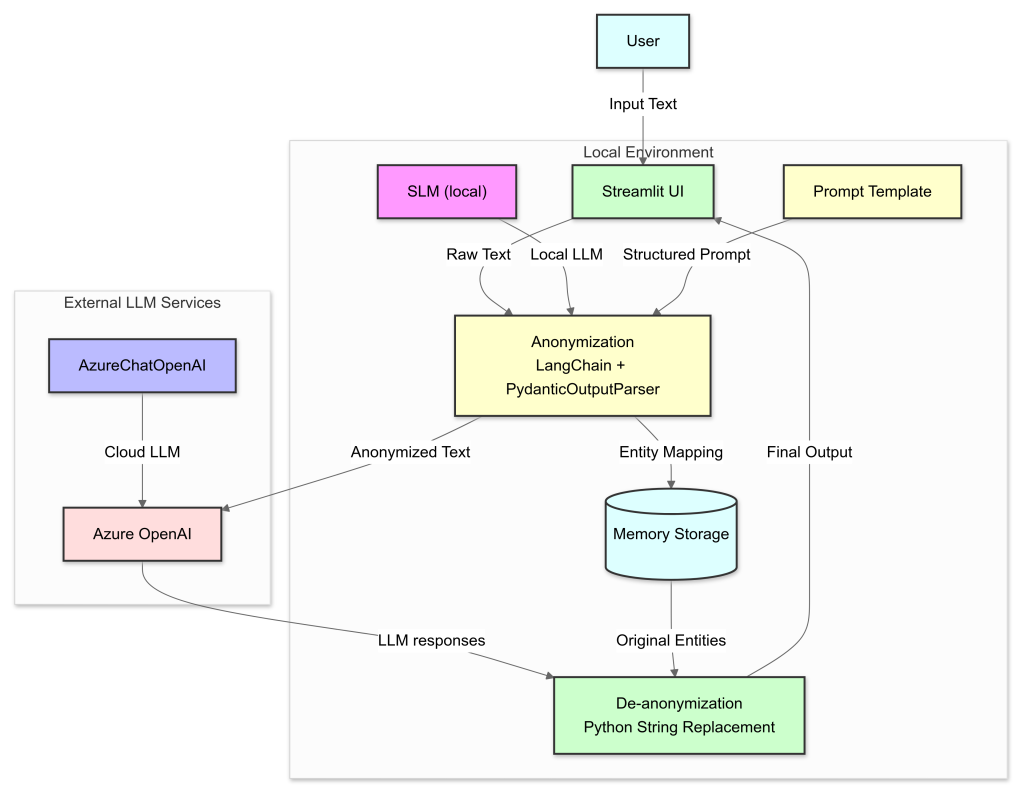
Technical Architecture
Our second approach uses a Small Language Model (SLM) with advanced anonymization techniques to protect sensitive information while maintaining the original text’s essence. It identifies and replaces Personally Identifiable Information (PII) with realistic alternatives. The process involves extracting sensitive data, anonymizing the text with AI models, sending it to Managed LLM APIs for further processing, and then de-anonymizing to provide a version that resembles the original text while ensuring privacy.
What Are Small Language Models (SLMs)?

Small Language Models (SLMs) are a new wave of AI models that offer impressive language processing capabilities while being significantly more resource-efficient than LLMs. These models, such as Gemma 2 , Meta Llama 3.1, Phi-3 , Mixtral 8x7B MoE, OpenELM are designed with fewer parameters, enabling them to perform specialized tasks with less computational power. This efficiency makes SLMs ideal for startups, academic researchers, and smaller businesses, allowing them to leverage advanced AI without the heavy hardware and energy demands associated with larger models.
SLMs excel in niche applications by focusing on specific datasets and utilizing advanced techniques like transfer learning and knowledge distillation. These innovations enable SLMs to achieve high performance in targeted areas, while maintaining cost-effectiveness and accessibility. As AI continues to evolve, SLMs are positioned to become a crucial tool for democratizing technology, offering scalable and sustainable solutions that can be easily integrated into various platforms, from mobile devices to cloud-based systems.
Local Processing with SLMs
At the core of our system is a local processing pipeline powered by a Small Language Model. We utilize Ollama, an open-source framework for running language models on local machines, to deploy and run the local models. This SLM serves as the primary component for initial text analysis and anonymization.
Key aspects of the local SLM processing pipeline:
- Entity Recognition: The SLM is trained to identify a wide range of sensitive information types, including but not limited to personal names, email addresses, phone numbers, physical addresses, and financial data.
- Anonymization: Once sensitive entities are identified, the model replaces them with realistic but fake alternatives. This process maintains the semantic structure of the text while obfuscating personal information.
- Contextual Understanding: Unlike rule-based systems, the SLM approach allows for context-aware anonymization, capable of handling complex linguistic structures and ambiguous references.
- Prompt Engineering: We employ carefully crafted prompts to guide the SLM’s behavior, optimizing for accuracy in entity recognition and consistent anonymization across multiple mentions of the same entity.
System Workflow
- Input Processing: User input is received through a Streamlit-based web interface, providing a user-friendly front-end for the system.
- Local Anonymization: The input text is processed by the local SLM (Small Language Models). This step identifies and replaces sensitive information with anonymized placeholders.
- Entity Mapping: A mapping of original entities to their anonymized counterparts is created and stored in local memory. This mapping is crucial for the later de-anonymization process.
- Cloud Processing : The anonymized text is sent to External LLM Services or Managed LLM APIs like Azure OpenAI, OpenAI API, Claude API for advanced processing for further tasks based on user requirements. This step leverages the power of larger language models without exposing sensitive data.
- De-anonymization: The system uses the stored entity mapping to replace anonymized placeholders with the original sensitive information, reconstructing the text with any modifications or additions from the cloud processing step.
- Output Presentation: The final, de-anonymized result is presented to the user through the Streamlit interface.
Data Modeling and Validation
We use Pydantic, a data validation and settings management library, to ensure robust handling of the anonymization results. We define a custom Pydantic model that structures the output of our anonymization process. Using Pydantic allows us to enforce a strict schema (JSON Schema) for our anonymization results, making it easier to work with the data throughout our pipeline and catch any inconsistencies early in the process.
Advantages of the SLM Approach
- Unlimited Entity Types: The model can be trained or prompted to recognize an arbitrary number of entity types, providing flexibility for various use cases and domains.
- Contextual Anonymization: SLMs can understand context, leading to more accurate and semantically appropriate anonymization compared to rule-based systems.
- Realistic Replacements: The model generates contextually appropriate replacements for anonymized entities, maintaining the coherence of the text.
- Adaptability: The SLM can be fine-tuned or prompted to handle domain-specific sensitive information, allowing for customization to different industries or use cases.
Technical Challenges
- Computational Overhead: While more efficient than large language models, SLMs still require significant computational resources for real-time processing.
- Latency Management: Local processing can introduce latency, especially for complex tasks.
- Model Hallucination: SLMs can sometimes generate incorrect or inconsistent information.
- Limited Context Window: SLMs typically have shorter context windows compared to larger models.
Performance Optimization
To continually enhance the system’s performance and accuracy, we focus on:
- Prompt Engineering: Iterative refinement of prompts used to guide the SLM’s behavior.
- Model Fine-tuning: Periodic fine-tuning of the local SLM on domain-specific datasets.
Benchmarking Anonymization Accuracy
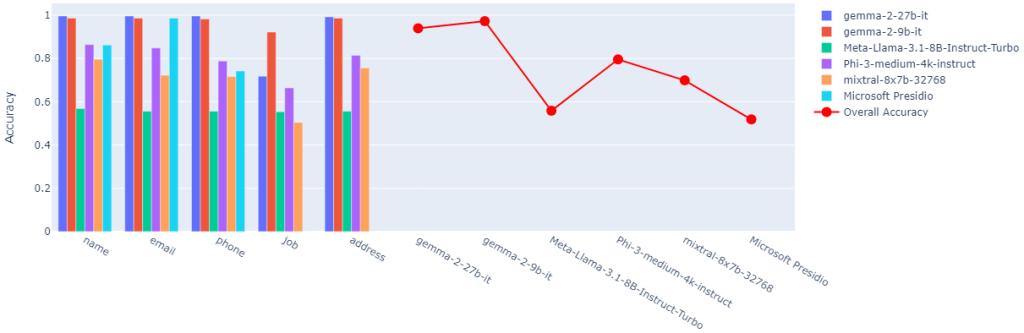
We benchmarked the anonymization accuracy of several Small Language Models (SLMs), including Gemma 2 (27B and 9B), Meta Llama 3.1 8B, Phi-3 medium, Mixtral 8x7B, and Microsoft Presidio. These models were tested on five categories: names, emails, phone numbers, job titles, and addresses. Gemma 2 led with the highest accuracy (93.96% for 27B, 97.24% for 9B). These findings underscore the importance of model selection in privacy-preserving AI systems and highlight the potential of newer SLM architectures in handling sensitive information.
We are Kainovation Technologies, Leading the way in AI, ML, and Data Analytics. Our innovative solutions transform industries and enhance business operations. Contact us for all your AI needs.