
In today’s digital world, the ability to efficiently extract information from official documents is a game-changer. The AI-Powered Driving License Information Extractor is a sophisticated tool designed to handle this challenge with precision. Leveraging state-of-the-art technologies like Optical Character Recognition (OCR) and Natural Language Processing (NLP), this extractor can seamlessly process driving licenses. This project streamlines the extraction process, making it highly accurate and user-friendly. This innovative solution not only enhances data accuracy but also significantly reduces the time and effort required for manual data entry. Join us as we delve into the technical marvels behind this powerful tool and explore how it transforms the way we handle essential documents.
Driving License Information Extractor🚘🪪 is the tool simplifies the process of extracting essential details from a driving license image, leveraging advanced OCR (Optical Character Recognition) technology and powerful regular expressions (RegEx). Whether you’re managing a fleet of drivers, handling administrative tasks, or simply digitizing your documents, our extractor streamlines the workflow, making it quick and easy to gather the information you need.
How It Works 💡
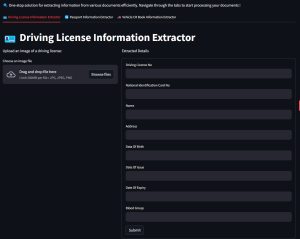
Using the Driving License Information Extractor is straightforward and user-friendly. Here’s a step-by-step guide to getting started:
- Upload an Image: Begin by uploading an image of the driving license. The tool supports common image formats such as JPG, JPEG, and PNG.
- Process the Image: Once the image is uploaded, our system processes it to extract text data using the PaddleOCR engine. This robust OCR tool ensures accurate recognition of text from the image.
- View Extracted Text: The extracted text from the driving license is displayed for your review. You can expand the section to view all the recognized text lines.
- Extracted Details: The tool then parses the OCR results to identify and extract key details using sophisticated RegEx patterns. These details include: Driving License Number, National Identification Card Number, Name, Address, Date of Birth, Date of Issue, Date of Expiry, Blood Group etc. The extracted information is automatically detected and populated into a dedicated form.
- Edit and Submit: You can review, edit, and confirm the extracted details through an interactive form. This ensures that all information is accurate before final submission.
Features 🪄
- Accurate OCR Processing: Utilizing PaddleOCR, a leading OCR technology, ensures high accuracy in text extraction.
- RegEx Precision: The use of regular expressions enhances the tool’s ability to accurately identify and extract specific information from the OCR text.
- User-Friendly Interface: The intuitive interface makes it easy for anyone to use the extractor without technical expertise.
- Editable Form: After extraction, details are presented in an editable form, allowing for quick adjustments and corrections.
- Support for Both New and Old Driving Licenses: The tool is designed to accurately extract information from both new and old formats of driving licenses, ensuring versatility and comprehensive support.
Key Technologies Used 🔧
The Driving License Information Extractor is built using a combination of advanced technologies to ensure accurate and efficient extraction of information from driving licenses. Below are the key technologies utilized in this project:
1. Streamlit
Streamlit is a powerful, easy-to-use framework for creating interactive web applications using Python. It allows for rapid development and deployment of data-driven applications. In this project, Streamlit is used to create a user-friendly interface for uploading driving license images and displaying the extracted information.
2. Optical Character Recognition (OCR)

For extracting text from driving licenses, we use PaddleOCR, an open-source OCR tool developed by Baidu. Known for its high performance and accuracy, PaddleOCR supports multiple languages and integrates seamlessly with Python.
why paddle OCR ?
- High Accuracy: After reviewing different open source OCR frameworks (including MMOCR, EASY OCR, PaddleOCR and HiveOCR) and different combinations of proposed models on internal benchmark and on the edge cases, a indisputable winner was PaddleOCR with an average accuracy of 0.8 and an acceptable performance on our edge cases. This result competes with the paid Google Cloud Vision OCR API on the best accuracy we measured. (Adevinta Tech Blog, “Text-in-Image 2.0: Improving OCR Service with PaddleOCR,” Medium, June 2023)
- Advanced Framework: Built on PaddlePaddle, PaddleOCR includes a range of pre-trained models for text recognition and document analysis.
- Versatility: It supports various text extraction tasks, including layout analysis and table recognition, making it highly adaptable to different document structures.
3. Image Processing

Pillow (PIL): the Python Imaging Library, is essential in the Driving License Information Extractor, allowing the opening, manipulation, and saving of various image formats like JPEG and PNG. It preprocesses the uploaded driving license images by converting, resizing, and enhancing them to ensure they are in optimal condition for accurate OCR processing. This ensures compatibility and improves the accuracy of the text extraction by the OCR engine
NumPy: NumPy is a fundamental package for scientific computing in Python. It is used for efficient manipulation of image data as arrays, which is necessary for image processing tasks. In this project, NumPy is used to convert images into an array format suitable for processing by PaddleOCR.
4. Regular Expressions (RegEx)
re: Regular expressions (RegEx) are pivotal in this project for accurately extracting targeted information from OCR results. They are utilized to define specific patterns that match driving license numbers, identification card numbers, dates, and other critical details. By applying these patterns, the tool efficiently identifies and retrieves the necessary information from the OCR-processed text, streamlining the data extraction process with precision and reliability.
5. User Interface Components
Streamlit Widgets: Various Streamlit widgets, such as file uploaders, text inputs, and forms, are used to create an interactive and user-friendly interface. They enable users to effortlessly upload driving license images, view extracted text, and edit or confirm details with simplicity. These widgets streamline the interaction process, providing an intuitive platform for managing and validating driving license information efficiently.
6. Data Handling
Python Dictionaries: Python dictionaries are used to store and organize the extracted information. This structure allows for easy access and manipulation of the data, making it simple to display and edit the extracted details within the Streamlit interface.
By integrating these technologies, the Driving License Information Extractor provides a seamless and efficient solution for extracting key information from driving license images. The combination of advanced OCR capabilities, robust image processing, precise pattern matching, and a user-friendly interface ensures high accuracy and usability.
The Driving License Information Extractor is a powerful tool designed to simplify the extraction of vital information from driving licenses. By leveraging advanced OCR technology and offering a user-friendly interface, it provides an efficient solution for managing driving license data.
We are Kainovation Technologies, Leading the way in AI, ML, and Data Analytics. Our innovative solutions transform industries and enhance business operations. Contact us for all your AI needs.